テキストを抽出 PDF
選択可能なテキストを .txt ファイルに抽出。スキャンには正直に対応し、OCR は行いません。 PDF Organizer は pdf-lib と pdf.js を使い、すべてブラウザ内で動作します。アップロード・保存・追跡は一切なし。タブを閉じればすべて消えます。
アカウント不要。サーバー側のファイルサイズ制限なし。一度読み込めばオフラインでも動作します。
テキストを抽出 PDF
PDF をドロップ
ファイルをそのままドラッグするか選択するだけ。好きなだけ読み込めます。
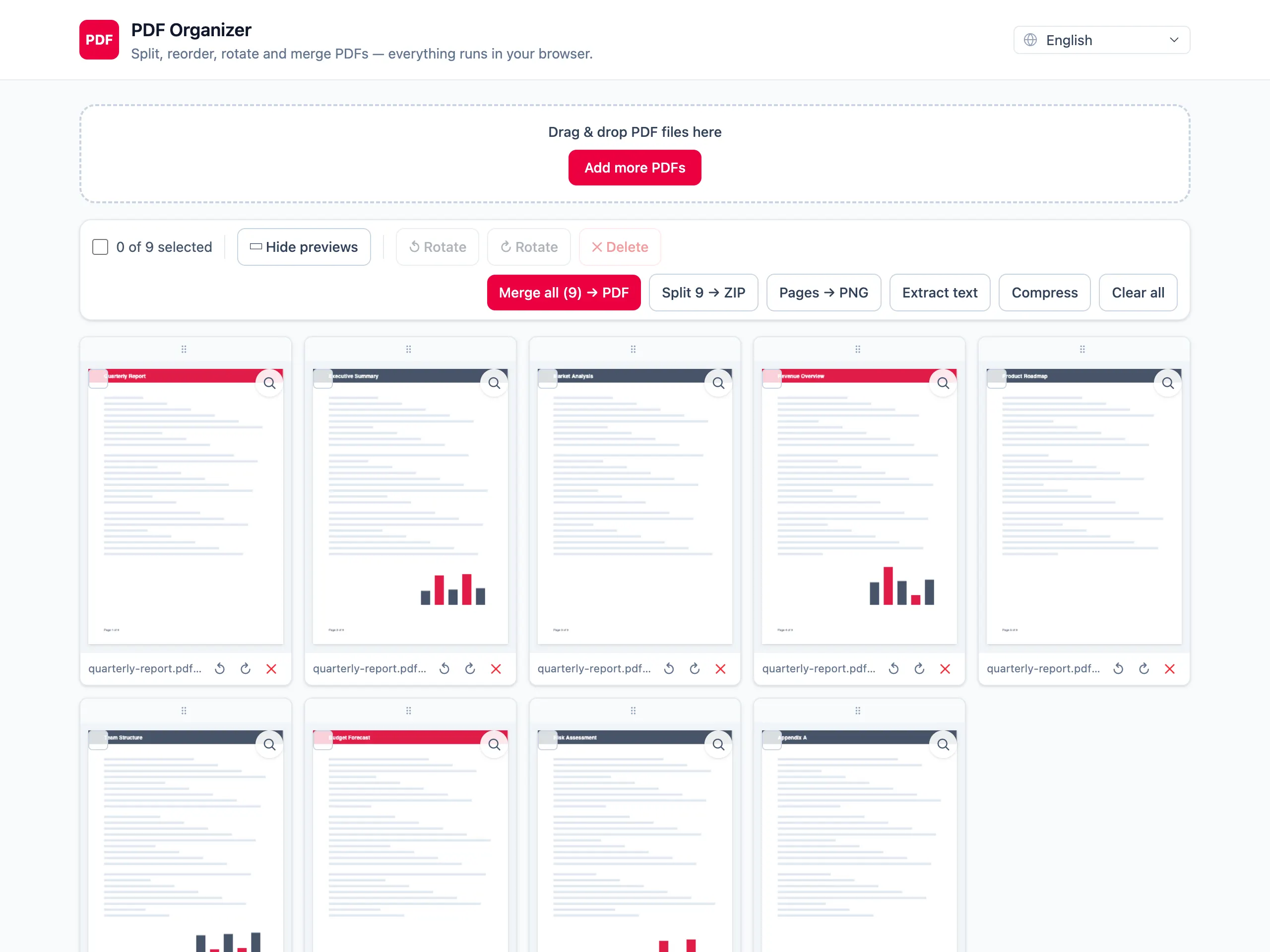
テキストを抽出 PDF
選択可能なテキストを .txt ファイルに抽出。スキャンには正直に対応し、OCR は行いません。
プレビューとエクスポート
どのページもプレビューしてから、1 つの PDF に結合するか、ページを ZIP でダウンロードします。
テキストを抽出 PDF
100% プライベート
すべての処理はブラウザ内で完結。サーバーもアップロードもありません。
テキストを抽出 PDF
選択可能なテキストを .txt ファイルに抽出。スキャンには正直に対応し、OCR は行いません。
ずっと無料
アカウント不要。サーバー側のファイルサイズ制限なし。一度読み込めばオフラインでも動作します。
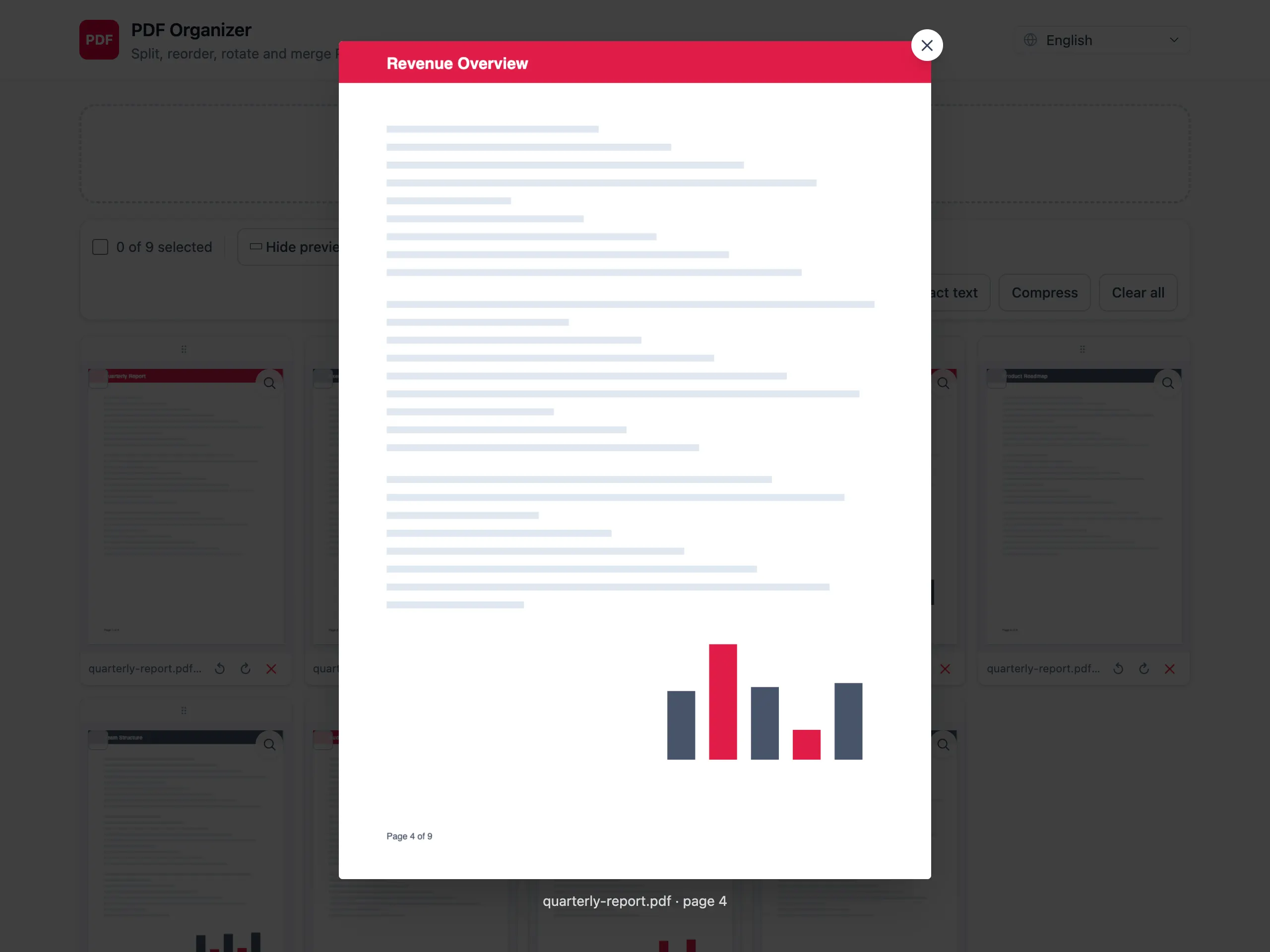
どのページもプレビュー
エクスポート前に、鮮明なフルサイズの描画を拡大して確認できます。
テキストを抽出 PDF — よくある質問
ファイルはどこかにアップロードされますか?
いいえ。PDF Organizer はすべてのファイルをブラウザ内で直接処理するため、アップロードせずに PDF を結合したり、サーバーに何も送信せずに文書を分割したりできます。ファイルが端末から出ることはありません。
本当に無料ですか?
はい、アカウント不要・試用期間なし・隠れた制限なしで完全に無料です。PDF をオンラインで無料圧縮できるほか、結合・回転・エクスポートも好きなだけ行えます。
アップロードせずに PDF を圧縮するには?
アプリを開いて PDF をドロップし、「圧縮」を選ぶだけです。未使用データを取り除く可逆圧縮か、画像の多いページをラスタライズする強力モードを選べます。処理はすべてブラウザ内で完結するので、何もアップロードせずに PDF をオンラインで無料圧縮できます。
スキャン文書でテキスト抽出すると何も出ないのはなぜですか?
テキスト抽出は、PDF にすでに存在する選択可能なテキストだけを読み取ります。スキャンや画像のみのページにはテキストレイヤーがなく、PDF Organizer は OCR を行わないため、そうしたページからは何も抽出されません。
オフラインでも使えますか?
はい。ページを一度読み込めば、処理はすべてローカルで行われるため、インターネットに接続していなくても PDF ファイルの分割・結合・圧縮ができます。
ファイルサイズの制限はありますか?
何もアップロードしないため、サーバー側による制限はありません。実質的な上限は端末のメモリだけで、非常に大きな PDF や高解像度の PDF は作業中により多くの RAM を使用します。